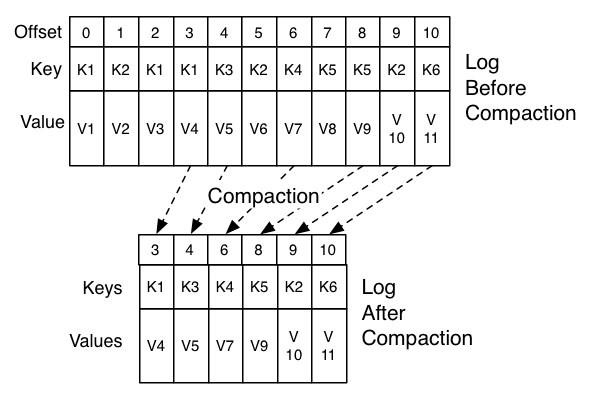
表连接是集合运算
嵌套循环连接
最传统、普遍、重要的连接方式
根据执行计划的执行顺序,解析下该连接方式的执行步骤
- 在列account_num的索引中,从满足查询条件account_num>’A000000139’的范围中读取第一个索引行。
- 利用account_num中的rowid从表ge_balance_account中读取对应的数据行,此时,所读取的数据行中所有列都将获得常量值,并利用查询条件site_type=29对所读取结果进行检验,如果满足条件则执行下一阶段的操作;否则,返回步骤1重新开始处理下一个索引行。
- 利用表a的site_name列的常量值去表s中site_name列的索引中寻找对应的索引行,如果没找到对应的行,匹配失败,返回步骤1重新处理下一个索引行;成功,则返回一条匹配记录。
特征
- 次序性。按次序处理驱动表查询范围中的每一行数据,按次序执行表连接。
- 先行性。依据优先读取的表中查询范围的大小,决定所需要处理的数据量。
- 选择性。即使为WHERE条件中所使用到的列都创建了索引,也不意味着这些索引全都会被使用。
应用准则
- 适合用于范围扫描方式。可以实现快速响应。
- 如果执行表连接的某一边表只有在获得了对方所提供的执行结果后才能缩减自身的查询范围,则必须选择嵌套循环表连接方式。
- 驱动结果集数据量较大时,执行效率不高,主要是因为会发生大量的随机读取。
排序合并连接

##执行步骤
- 从表s的site_type列索引中读取满足查询条件s.site_type=29的数据行后,并按照site_name的值对数据进行排序。
- 从表a中读取满足查询条件的数据行后,也按照site_name的值进行排序。
- 对两个排序后的数据按照site_name相等的要求进行合并
特征
- 并行性。根据自身的查询条件读取条件并排序。
- 独立性。不需要从其他集合中获取处理结果。
- 必须按照全局扫描的方式进行处理。
- 与表的连接方向无关
- 在很大程度上减少随机读取次数
应用准则
- 在只能按照全局扫描方式来处理的SQL中,可以使用该方法
- 在不需要获取对应表中任何常量值也可以充分地实现缩减查询范围的条件下,使用该方法很有效
- 不适合OLTP类型的系统,因为排序是非常昂贵的操作。
随机读取的代价:在最坏的情况下,为了读取某一行的数据,需要从磁盘将整个表格数据读入。
排序的代价:对内存造成了很大的负担
哈希连接

术语及基本概念
Hash Area
内存空间,存储包括:位图矢量(向量)、哈希表和分区表。
位图矢量:就是Build Input中的值的集合(集合的唯一性),主要用于过滤操作(如果在Probe Input过程中所读取的数据行不存在于位图向量中,则没必要为其在分期中分配空间)
哈希表中存储各个分区的位置信息。
分区(Partition)
聚簇(Cluster)
在哈希聚簇的时候,把具有相同哈希值的行存储在统一聚簇中。(那么跟分区又有什么区别呢? 书中有个比喻,如果将柜子比作分区,那么cluster就是柜子中的抽屉),好吧,这个意思就是:第一次哈希得到的是分区值(即映射到分区上),第二次哈希得到的值是映射到分区内的聚簇上。
Build Input
提前执行的读取准备操作
Probe Input
后来读取的操作
In-Memory哈希连接
能将Build Input全部加载到Hash Area的情况
指将Build Input全部存储在内存中并未其创建哈希表,在扫描Probe Input的同时实现连接。

- 根据统计信息选择结果集较小的作为Build Input
- 确定分区数fan-out
- 经过第一次hash运算,确定所在的分区
- 第二次hash运算,得到hash_value_2
- 根据hash_value_2创建哈希表,并将对应的列存入相应分区的聚簇中
- 根据连接列的值创建位图向量
- 按照上面的步骤对表中所有数据对象进行处理
- 从现在开始从Probe Input中读取满足查询条件的数据
- 第一次hash运算,并利用位图向量对Probe Input对象进行过滤,若没有通过过滤,则返回并重新读取下一个对象
- 对于通过的对象进行第二次hash运算,利用hash表读取相关分区和聚簇找到相应的行,找不到,重新读取下一个
- 执行连接操作,将结果发送到运输单位
- 反复8~11的操作
- 运输单位被填满后直接返回结果
- 按照以上步骤对Probe Input进行处理,直到结束为止。
疑问:位图向量中到底存储的是什么?是连接列的值呢,还是经过第一次哈希得到的值呢? OK,还是统一确定为连接列的唯一值好了
特征
- 不需要使用索引
- 允许实现局部范围扫描
延迟哈希连接
不能完全加载,需要将超出的部分存储在磁盘中
前6步基本一致
- 如果超过了Hash Area的范围,则将分区的地址信息存储在分区表中,并将超出的部分移到磁盘上对应的分区上,后面如果寻找到分区并利用地址信息,就再次将磁盘 上的数据加载到内存中实现连接操作
- 处理Bulid Input直到结束为止
- 从Probe Input的查询范围内读取数据,进行第一次哈希运算,并利用位图向量对结果进行过滤
- 对通过过滤的进行第二次哈希运算,如果对应的Build Input对象存在于内存中则读取哈希表进行连接操作,否则,将Probe Input对象存储在其所属的分区中
- 将无法实现连接的分区存储在磁盘上
- 按照以上方式对Probe Input的对象进行连续处理
- 内存中的连接操作处理完毕,接下来,利用分区表中的地址信息从磁盘上将没有被连接的分区对载入到内存中
- 从重新载入到内存中的各个分区中选择一个最小的集合为其创建哈希表。实现角色互换
- 对重新确定的Probe Input进行扫描,利用哈希表进行连接。按照这种方式对磁盘中剩余的所有对象进行处理,直到结束为止
特征
- 延迟哈希连接主要被使用在需要处理大量数据的批处理应用程序中。
- 哈希连接能弥补sort merge join最大的弱点(对海量数据执行排序操作所需要付出的代价过大)
- 利用位图向量,对另一个集合进行过滤,这一点与嵌套循环连接很相似。
- 延迟哈希无法实现局部范围扫描
- 一般而言,指定的Hash Area大小基本上是排序区域大小的1.5倍
- 在处理非海量数据的情况下,当额外要求对连接列的值进行排序操作时排序合并更有效
半连接
- 在使用了子查询的时候为了实现子查询与主查询之间的连接而使用的一种广义表连接
- 子查询可以无条件的继承主查询的所有属性,反之不成立。(主查询所具有的各个列可以被使用在子查询中)
- 结果集合始终与主查询的集合类型相同
嵌套循环型半连接

为了维护主查询集合类型的完整性而附加性地增加了SORT(UNIQUE)操作
在这里,子查询被优先执行,因此可以将子查询定义为“提供者”,其执行结果将以常量值的形式提供给主查询Where条件中的连接列。

这个SQL的执行计划中,优先执行的是主查询,然后利用其执行结果与子查询进行了连接。因此在这里可以将自查询定义为“检验者”,对主查询的执行结果进行了检验。
实现这一转变的关键在于
- 主查询中添加了查询条件
t.site_type=30 - 在子查询中添加了
a.site_id = t.id这一句看上去重复的连接条件,这个连接条件可以从逻辑上确保子查询不可能被优先执行
过滤型半连接

哈希型半连接

限制条件:
- 在子查询中只能使用一个表
- 在子查询中再次嵌套使用子查询时无法使用哈希连接
- 连接条件只能是相等
- 在查询中不能使用Group BY,Connect by, rownum等限制条件