带着以下两点疑问,进行kafka server的Log管理源码的分析:
- producer遇到 NOT_LEADER_EXCEPTION 是在何时产生的
- 消息是如何在ISR中备份的
下面以从上往下的方式对一条消息写入磁盘的全链路进行分析
KafkaApis
kafka apis反映出kafka broker server可以提供哪些服务,
broker server主要和producer,consumer,controller有交互,搞清这些api就清楚了broker server的所有行为
handleProducerRequest
- 该方法用于处理Client的producer请求,
ApiKeys = 0 - 从 RequestChannel 中获取请求,然后根据acks规则进行反馈
- 写入磁盘的动作在
replicaManager.appendRecords中完成
ack规则
| acks | 规则 |
|---|---|
| 0 | producer不需要等待ack,server收到消息后直接反馈 |
| 1 | leader成功写入后反馈给producer |
-1 (kafka-client中配置为"all") |
在ISR中所有replicas都写入消息后才进行反馈 |
ReplicaManager.appendMessages
- 先将消息写入leader的log中(正常情况就是当前这个broker)
- 将消息写到ISR的其他备份中
- 超时或者ack规则满足时进行反馈操作(执行回调函数:
responseCallback)
//写到leader的log |
ReplicaManager.appendToLocalLog
当topic为内部topic(即
__consumer_offsets),并且不允许往内部类中写消息时,抛出 InvalidTopicException
val info = partitionOpt match { |
Partition.appendRecordsToLeader
判断当前broker是否是parition的leader
def getReplica(replicaId: Int = localBrokerId): Option[Replica] = Option(assignedReplicaMap.get(replicaId)) |
- assignedReplicaMap:用于存放每个partition对应的leader已经replicas
- 通过比较leaderId与localBrokerId,判断当前broker是否就是leader
- 如果不满足,那么将抛出NotLeaderForPartitionException
备份数不满足条件的消息不会写入
val log = leaderReplica.log.get |
Log.append
- 返回的格式为
LogAppendInfo,包含第一条及最后一条offset信息 - 找到该Partition在当前broker上面最新的segment,如果塞不进去 就新建一个segment
- 将消息添加到segment中
- 更新segment的
LogEndOffset为最新添加消息的lastOffset+ 1ByteBufferMessageSet
append方法中传入的消息集的数据结构为ByteBufferMessageSet(注:在0.10.2.0版本后引入新的结构:MemoryRecords),父类为Messageset,其结构如下图所示:
一个有效的MessageSet的最小长度为12字节
Message的组成
Message在magic不同的情况下有不同的结构:
迭代器的实现
internalIterator是ByteBufferMessageSet实现的迭代器,迭代单位是MessageAndOffset
magic的值是由server中Log的配置属性:
message.format.version决定的,0.10.0之前的版本的magic值为0,之后的版本为1
迭代的过程也是对消息的有效性的检验过程:
- ByteBuffer(对应MessageSet)的长度是否< 12
- 消息体(对应Message)的长度是否 < 魔术为0时Message的头部长度(4+1+1+8+4 = 18)
- ByteBuffer的长度是否<消息体的长度(否则就表明消息不完整)
满足以上条件的消息一定是无法继续迭代的
由于消息的载体实现的是ByteBuffer,那我们就从Buffer的操作的角度来看看message和offset是如何被迭代取出来的:
假设当前接收到一个新的ByteBuffer,下面进行迭代:
- 获取buffer的片段(第一次算是拷贝):topIter = buffer.slice()
- 获取offset(获取前八个字节): offset = topIter.getLong()
- 获取size(获取紧接着的四个字节):size = topIter.getInt()
- 获取message(当前position指向message的开始位置,截取后续size大小的就可以得到message):message = topIter.slice; message.limit(size)
- 将topIter的position指向下一条MessageSet: topIter.position(topIter.position + size)
LogAppendInfo的生成
LogAppendInfo主要包含四个属性,用于描述message set
: firstOffest:第一条消息的offset
: lastOffset:最后一条消息的offset
: maxTimestamp:消息里面包含的最大时间戳
: offsetOfMaxTimestamp:最大时间戳消息的offset
analyzeAndValidateMessageSet方法实现了LogAppendInfo的生成,根据上面提到的迭代器对MessageSet中的消息进行迭代处理,找出并记录offset和timestamp信息,此外也对每条消息进行检验:
- 每条消息的大小不能超过
max.message.bytes所定义的 - 每条消息必须通过循环冗余校验
消息的进一步校验
对消息的进一步校验及转化是在validateMessagesAndAssignOffsets方法中完成的。该方法的参数中涉及到一些概念:
1.topic清理策略
log.cleanup.policy配置项控制着消息在segment中持久化的策略,目前有两种策略供选择:delete和compact,默认选项为delte。
- delete的策略很好理解,就是当segment时间或者大小到期了就删除。
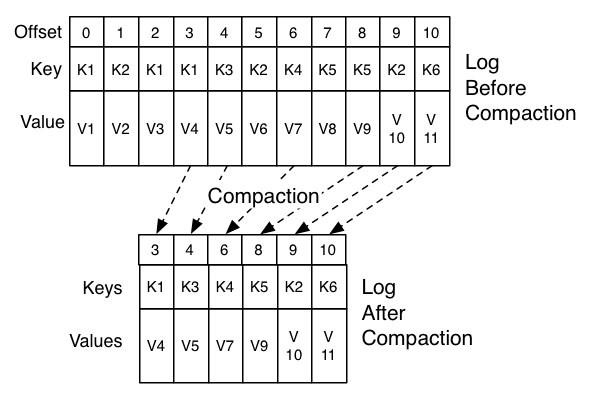
compact的策略是为了满足系统灾后恢复的需求,该选项是针对topic的,比如存在某个topic:email_topic用于存储用户变更的email信息,key=userId,value=emailAddress,compact操作就是在日志删除过程中保留每个userId最新的数据,如果系统崩溃了也能通过该topic获得用户最新修改的email地址。下面的图很好的诠释了这种操作:
2. 版本与magicValue
由于kafka的版本更新速度比较快,为了能让新的server版本兼容老的client版本以及server的滚动升级的实现,提供了
message.format.version配置项定义consumer及Producer的API版本。- 不同的API版本对应不同的magicValue,其中0.9.0.X版本之前(包括该版本)的magicValue未0,之后的都为1
当前我们生产环境使用的API版本为0.10.0.0,server的版本为0.10.1.1
3. 解析非压缩消息
producer可以选择是否对消息进行压缩
message.timestamp.type:时间戳类型
: CreateTime:消息的创建时间<默认值>
: LogAppendTime:添加到log的时间
message.timestamp.difference.max.ms:最大时间间隔,表示收到的消息中的时间戳与当前时间的差的最大容忍值。
对非压缩消息的进一步处理的过程依然是ByteBuffer的操作过程:/*主要目的是获取maxTimestamp和offsetOfMaxTimestamp*/
var messagePosition = 0
var maxTimestamp = Message.NoTimestamp
var offsetOfMaxTimestamp = -1L
//将position位置存到mark中
buffer.mark()
while (messagePosition < sizeInBytes - MessageSet.LogOverhead) {
buffer.position(messagePosition)
//offsetCounter是server维护的下一个offset的值
buffer.putLong(offsetCounter.getAndIncrement())
val messageSize = buffer.getInt()
val messageBuffer = buffer.slice()
messageBuffer.limit(messageSize)
val message = new Message(messageBuffer)
//以上的操作能获取到MessageSet中的一条message
if (message.magic > Message.MagicValue_V0) {
validateTimestamp(message, now, timestampType, timestampDiffMaxMs)
if (message.timestamp > maxTimestamp) {
maxTimestamp = message.timestamp
offsetOfMaxTimestamp = offsetCounter.value - 1
}
}
//将buffer的position移到后一条消息的头部
messagePosition += MessageSet.LogOverhead + messageSize
}
//根据mark恢复position
buffer.reset()
经过上面的操作,MessageSet中的offset被server重新设置了,并且maxTimestamp之类的信息重新收集了。这些信息在append操作中会被使用:validMessages = validateAndOffsetAssignResult.validatedMessages
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.offsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1
其中:
: validMessages就是处理完后的MessageSet
: offset是上面使用到的offsetCounter,即下一个offset值。为什么要-1?因为上面执行了getAndIncrement()操作,因此当前的offset指向的依然是下一个offset值
4.压缩消息的处理
producer的压缩策略必须与broker一致,如果不匹配那么将不会解压缩消息
以下几种情况不会对压缩消息进行解压处理:
- topic指定了压缩策略,但是发送的消息中没有key(会报错)
- 消息体与server的magic值不一致
找到合适的segment
- 一个topic由多个parition组成,每个partition又存在多个segment
- 每个segment的大小由
log.segment.bytes控制,下面是segment大小设置为1024的broker上某个partiton的Log情况:[test-0]$ du -smh *
0 00000000000000017699.index
4.0K 00000000000000017699.log
4.0K 00000000000000017699.timeindex
0 00000000000000017724.index
4.0K 00000000000000017724.log
0 00000000000000017724.timeindex
- 每个log的命名规则是取该log中 下一个 offset的值(
logEndOffset);- 以index结尾的offset index文件的作用是将offset映射到物理文件中
- timeindex文件将时间戳与segment中的逻辑offset联系起来
满足以下几个条件之一时会创建新的segment:
- 当前segment容不下最新的消息
- 当前segment非空,并且达到了
log.roll.hours的时间 - offset 或者 time index满了
下面是写消息时创建出新的segment时server的输出日志:[2017-04-05 17:14:29,776] DEBUG Rolling new log segment in test-11 (log_size = 1006/1024}, index_size = 0/1310720, time_index_size = 1/873813, inactive_time_ms = 184193/604800000). (kafka.log.Log)
将消息添加到LogSegment中
LogSegment的参数主要有:
: log:File类型的MessageSet,该Set中包含一个FileChannel,能够从ByteBuffer中读取数据
: index: OffsetIndex,逻辑Offset到物理文件位置的索引
: timeIndex:TimeIndex,时间戳到物理位置的索引
: baseOffset:第一个offset
写消息的操作:
将AppendInfo中的消息写入到LogSegment中的FileChannel中def writeFullyTo(channel: GatheringByteChannel): Int = {
buffer.mark()
var written = 0
while (written < sizeInBytes)
written += channel.write(buffer)
buffer.reset()
written
}
_size.getAndAdd(written)
FileMessageSet的search操作
根据offset或者时间戳是从Log中读取消息的常见方法。FileMessageSet提供对应的两个方法:searchForOffsetWithSize和searchForTimestamp。前者是从FileMessageSet的给定位置往后搜索第一个大于等于目标offset的消息,返回的是Offset&Position,后者是从给定位置往后搜索第一个时间戳大于等于目标时间戳的消息,返回Timestamp&Offset。
下图描述的是从0开始搜索offset≥1003的消息:
写OffsetIndex
OffsetIndex中并不会记录所有Offset的映射关系,写入Index的时机由index.interval.bytes参数(default:4096)控制,当segment中积累的消息数量大于该参数时,会将此次写入segment中的MessageSet的第一个消息的offset写入OffsetIndex中:if(bytesSinceLastIndexEntry > indexIntervalBytes) {
index.append(firstOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += messages.sizeInBytes
index.append的具体操作如下:if (_entries == 0 || offset > _lastOffset) {
mmap.putInt((offset - baseOffset).toInt)
mmap.putInt(position)
_entries += 1
_lastOffset = offset
}
上面的操作是将offset相对这个Segmet的baseOffset的偏移值以及物理地址填入到OffsetIndex中定义的MappedByteBuffer。
之所以使用相对偏移值是出于节省存储空间的考虑,相对偏移值只需要4位空间就能存储,而MessageSet中的offset占8位。
写TimeIndex
在每次执行append操作时,TimeIndex记录的是最大时间戳及其对应的offset的索引。if (timestamp > lastEntry.timestamp) {
mmap.putLong(timestamp)
mmap.putInt((offset - baseOffset).toInt)
_entries += 1
}
写入Buffer中的是时间戳以及相对偏移量
更新LogEndOffset
上面的分析中提到过每个Log都维护了一个记录下一个offset的变量——nextOffsetMetadata,该变量是LogOffsetMetadata类型的:
: messageOffset:绝对偏移值
: segmentBaseOffset:LogSegment的baseOffset值
: relativePositionInSegment:LogSegment的大小(字节数),根据字节数可以定位到这条消息在segment中的物理位置
每次append操作都会执行:nextOffsetMetadata = new LogOffsetMetadata(messageOffset, activeSegment.baseOffset, activeSegment.size.toInt)
其中:
- messageOffset为 AppendInfo.lastOffset+1
- activeSegment是当前可用的segment
- activeSegment.size由
_size.get(),这个_size正是在上面往segment中写消息时进行更新的,每次增加的值是写入channel中的字节数。
下面这张图生动描述了这个更新的操作:
- 绿色的代表activeSegment,当前的nextOffsetMetadata为10(指的是messageOffset)
- 写入10条消息后,nextOffsetMetadata更新为21
- 再次写入10条消息后,更新为31
- 再来10条消息,无法写入,执行roll操作新建一个segment,messageOffset值未改变,不过activeSegment变化了
- 将10条消息写入新的segment中,更新为41